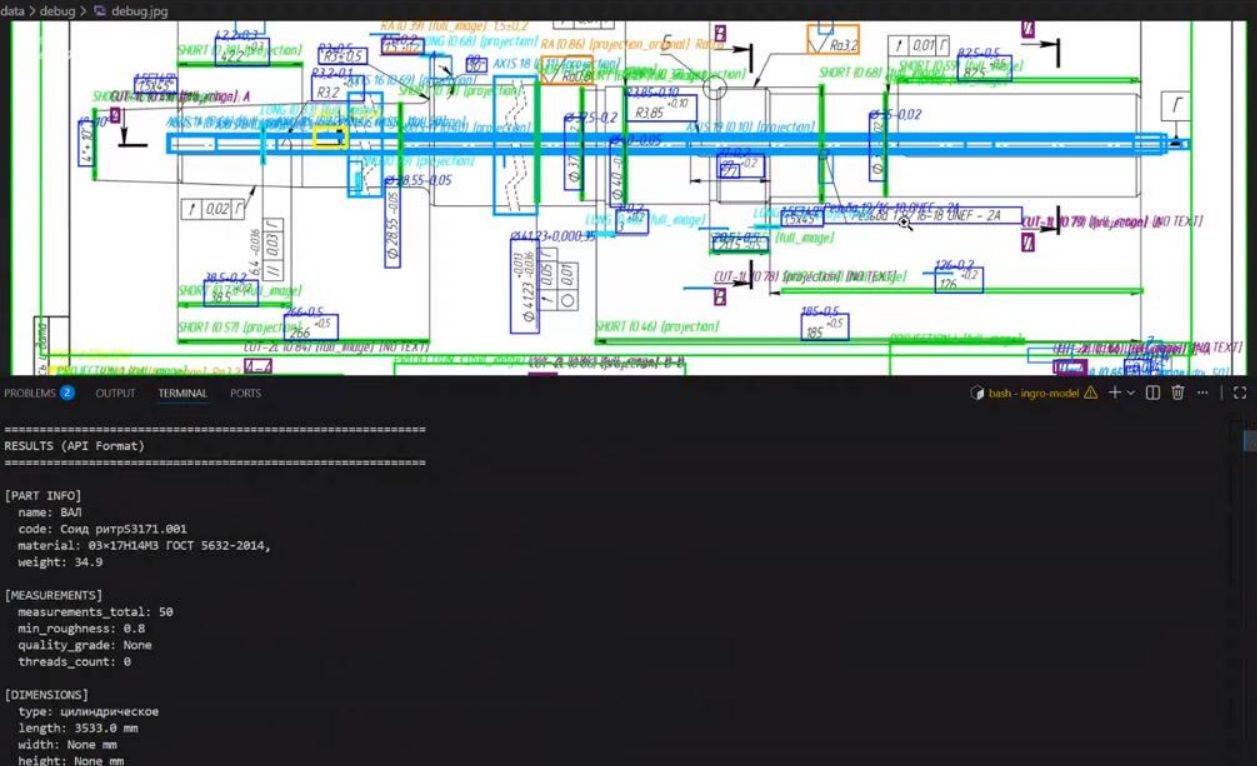
В машиностроении скорость ответа клиенту часто упирается не в станки и не в производственный план. Приходит запрос на изготовление детали, к нему приложен 2D-чертёж (PDF/скан/фото), и дальше начинается ручная работа технолога: понять геометрию, вытащить размеры, резьбы, шероховатости, квалитеты, материал/массу, оценить трудоёмкость. На одну позицию легко уходит 4–8 часов — даже если специалист опытный и документ читаемый. В результате коммерческое предложение формируется медленно, заявки "остывают", а производители теряют скорость реакции.
Мы в NeuroCore разработали ИИ-решение, который превращает 2D-чертёж в структурированные параметры детали и передаёт их по API в расчётный алгоритм заказчика (на стороне платформы). То есть система не "угадывает цену", а автоматизирует самое затратное: извлечение данных из документа в форме, удобной для расчёта.
Вы можете сразу перейти к кейсу, а можете прочесть данную статью, чтобы понять, как это работает.
Почему 2D-чертёж — это сложнее, чем кажется
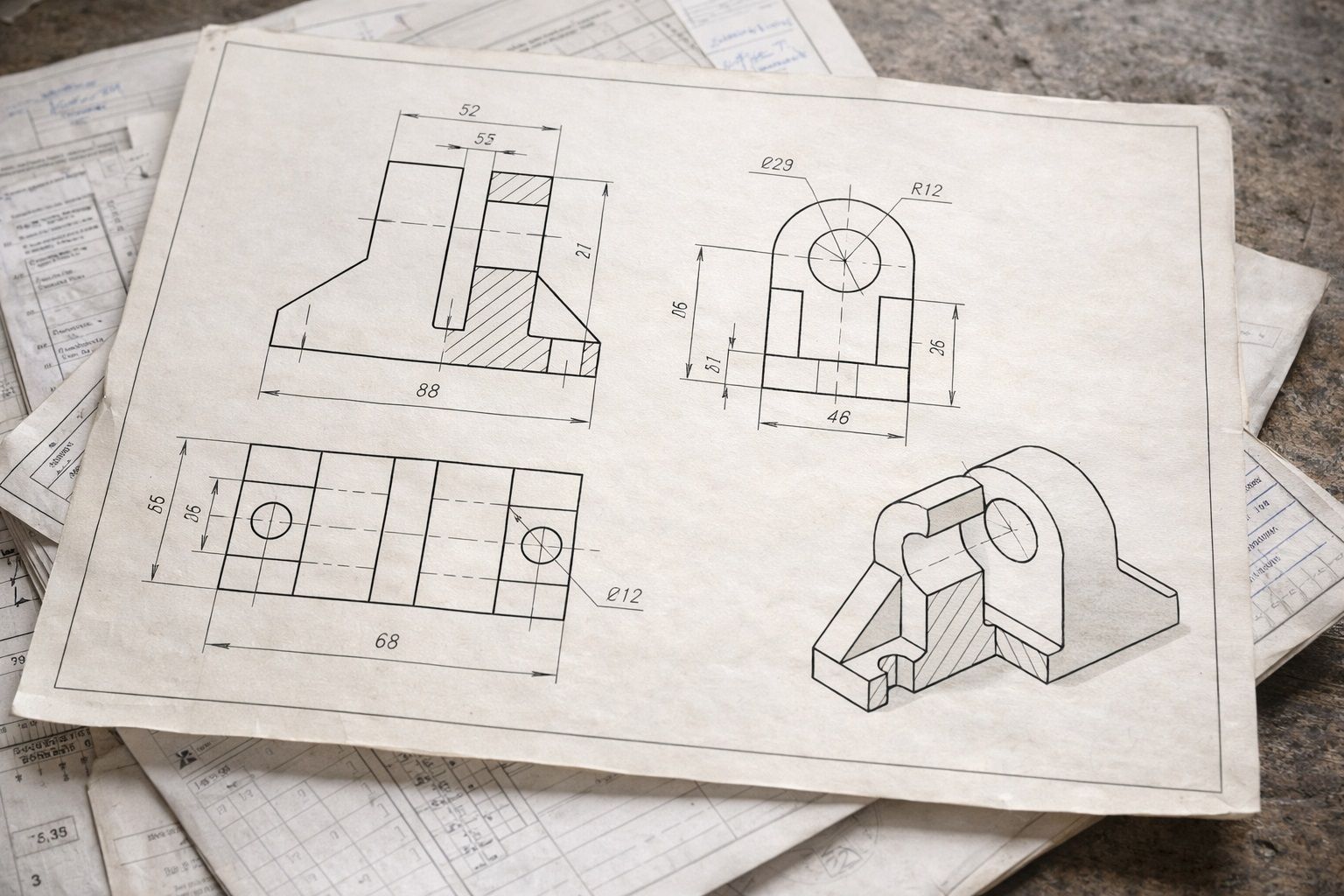
В 3D-модели геометрия уже "машиночитаемая": можно достать размеры и топологию напрямую. 2D-чертёж — это другой мир. Там важное спрятано в оформлении: размерные линии, выноски, символы, обозначения шероховатости, резьбы, квалитеты, подписи в рамке. Плюс качество исходников: многолистовые PDF, старые сканы, разный шрифт, плотная компоновка, пересечения линий.
Поэтому "просто OCR" не решает задачу. Нужно одновременно:
- найти структуру листа (рамка, основное поле, зоны текста),
- понять, где именно размеры и технические обозначения,
- распознать текст и числа,
- корректно интерпретировать их в контексте (например, отличить диаметр ⌀ от линейного размера),
- отдать результат в строгой структуре, чтобы расчётная часть могла ему доверять.
Именно под это и строится архитектура: предобработка → детекция элементов → OCR → парсинг и валидация → API.
Что именно система извлекает из 2D-чертежа
Мы заложили практичный набор параметров, который реально нужен для первичного расчёта производства:
Из рамки чертежа (метаданные):
- наименование детали,
- шифр,
- материал,
- масса.
Если материал или масса отсутствуют — система не «додумывает», а возвращает признак «не найдено», чтобы не вносить скрытые ошибки в расчёт.
Из поля чертежа (технологически значимые признаки):
- общее количество измерений,
- минимальная шероховатость (Ra),
- квалитет самого точного измерения,
- количество резьб,
- габариты изделия (для прямоугольных: длина/ширина/высота; для цилиндрических: длина и диаметр).
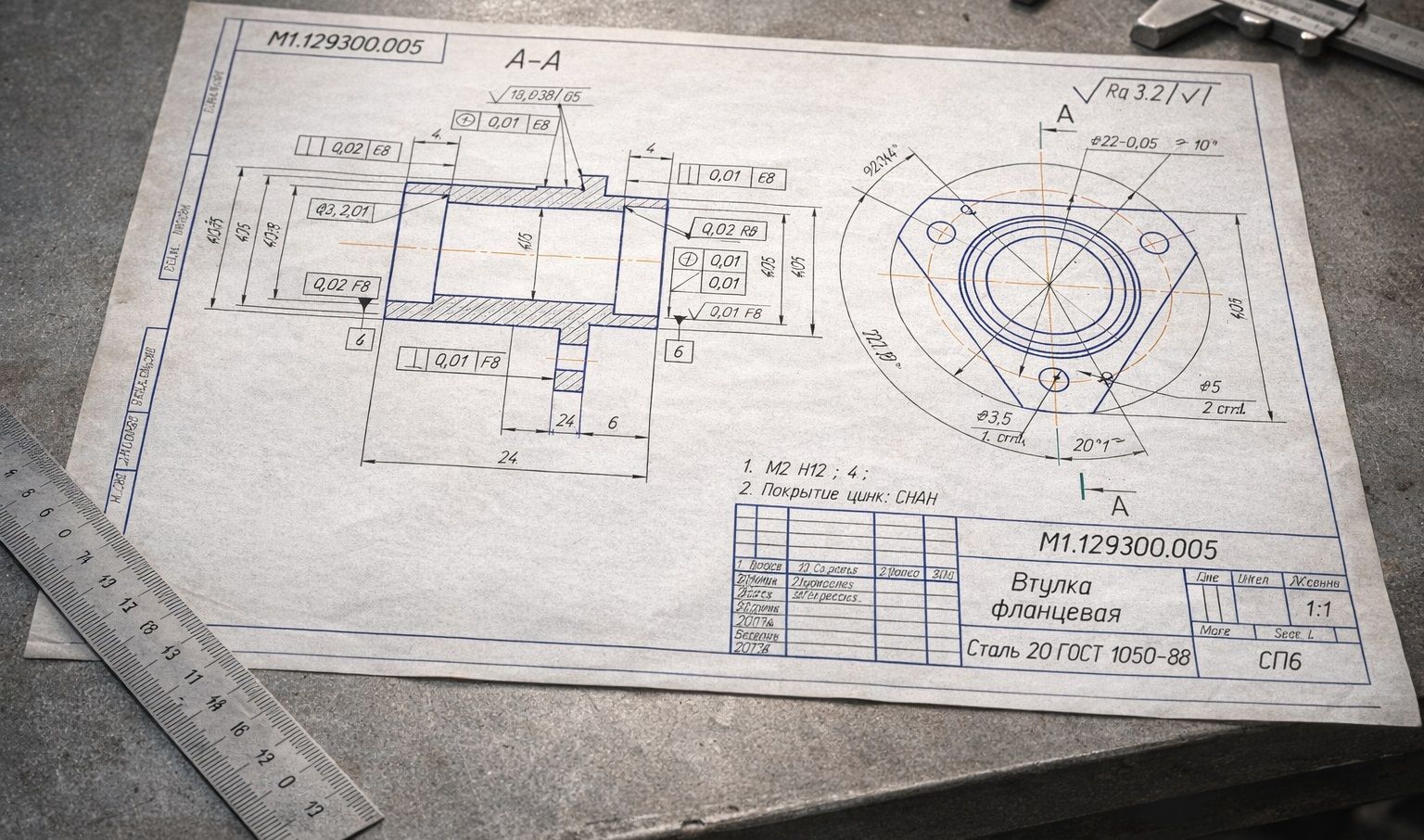
- Поддерживаемые форматы на входе: PDF и растровые изображения (JPG/PNG/BMP/TIF и др.).
- На выходе — структурированный JSON, который уходит в расчётную систему заказчика по API.
Как это работает на производстве, а не в презентации
Чтобы такая система была полезной, она должна быть устойчивой к реальности. Поэтому мы проектировали её как конвейер с контролем качества на каждом шаге:
1) Предобработка документа
PDF часто нужно корректно отрендерить в растр, выровнять контраст, убрать шум, нормализовать масштаб. Это повышает стабильность детекции и OCR на «живых» документах, а не только на идеальных выгрузках.
2) Детекция нужных зон и обозначений
Модель выделяет рамку и области, где с высокой вероятностью лежат метаданные и размерные элементы. Это критично: если OCR «прочитает всё подряд», он утонет в подписи, штампах, таблицах и мусоре.
3) OCR и семантический парсинг
Дальше включается распознавание текста (OCR) и слой интерпретации: числа, единицы измерения, символы (⌀, R, M…), форматы записи резьб, шероховатости, квалитетов.
4) Валидация и правила безопасности
Система проверяет входные данные на здравый смысл (диапазоны, формат, конфликтующие значения). Если уверенности нет — возвращает «не найдено/нужно уточнение», а не подменяет реальность "красивым ответом". В промышленности ошибка хуже, чем отсутствие данных: ошибка потом превращается в неверное КП и спор на закупке.
5) Передача по API
Распознанные значения уходят в расчётный сервис заказчика через REST/HTTP.

Как мы меряем качество, чтобы этим можно было управлять
В таких проектах "точность 95%" ничего не значит без разложения по компонентам. Поэтому мы фиксируем метрики отдельно:
- для детектора данных — целевой ориентир mAP > 80%;
- для OCR — Accuracy > 80%;
- дополнительно считаем TP/TN/FP/FN, чтобы видеть профиль ошибок и управлять улучшениями.
Это важно не только для отчёта, но и для эксплуатации: когда качество падает (например, поменялся шаблон чертежей у крупного поставщика), это должно быстро диагностироваться и лечиться — данными, дообучением, правилами.
Экономика: что меняется для бизнеса
Когда извлечение параметров автоматизировано, выигрывает не "ИИ ради ИИ", а операционная модель:
- технологи меньше времени тратят на расшифровку документа и ручную передачу параметров (автоматизация до 70% рутинных операций в контуре расчёта);
- платформа быстрее отвечает заказчику и не теряет заявки из-за долгого ожидания;
- результат становится более воспроизводимым: меньше зависит от загруженности конкретного специалиста и человеческого фактора;
- появляется масштабирование «по клику»: параллельная обработка документов без участия оператора.
По данным проектного контура MVP, точность расчёта в пилотной версии была около 85% — на уровне, достаточном, чтобы подтвердить применимость подхода и дальше добирать качество на расширении данных и покрытии краевых случаев.
Сколько занимает внедрение ИИ-решения по распознаванию чертежей?
Если вы хотите, чтобы модуль реально работал в проде, нужно пройти нормальный инженерный цикл: собрать датасет, обучить модели, сделать интеграцию, прогнать пилот на реальных документах, поставить на сервер.
В одном из типовых планов работ это выглядит так: ТЗ (1 месяц), создание MVP (около 2,5 месяцев), пилот и установка на сервер заказчика (ещё 1 месяц). Общая длительность — порядка 4,5 месяцев.
В таких системах "сложность сидит в данных" — в разнообразии чертежей, качестве сканов, нестандартных обозначениях и исключениях. Чем раньше вы начинаете собирать реальные документы и спорные примеры, тем быстрее растёт качество.
Что важно предусмотреть заранее
Если планируете такой модуль у себя (внутри завода, инжинирингового отдела или платформы), вот три вещи, которые лучше не откладывать:
- Единый формат результата: договориться, какие поля обязательны, какие опциональны, какие значения допустимы и как маркировать «не найдено». Это спасает интеграцию.
- Набор "сложных" чертежей: заранее собрать документы, которые технологи считают самыми неудобными (сканы, плотная компоновка, нестандартные символы). На них и должна держаться устойчивость.
- Контур качества в эксплуатации: мониторинг метрик, логирование ошибок, процесс дообучения. Иначе пилот будет красивым, а промышленная эксплуатация — болезненной.
Если в вашем бизнесе 2D-чертежи — это "слабое место" в расчёте стоимости, планировании или запуске производства, мы можем автоматизировать этот этап под ваши процессы.
Мы не продаём универсальное решение.
Мы проектируем и внедряем модуль распознавания 2D-чертежей под конкретную задачу: с учётом ваших форматов документов, правил расчёта, требований к точности и интеграции с ERP/PLM/внутренними сервисами.
Что вы получаете:
- анализ применимости именно для вашего массива чертежей;
- пилот на реальных документах;
- интеграцию по API в вашу систему расчёта;
- архитектуру, которую можно масштабировать и поддерживать;
- прозрачные метрики качества, а не «магические проценты».
Если хотите понять, можно ли сократить время обработки чертежей с часов до минут в вашем контуре — обсудим задачу и сделаем предварительную техническую оценку.



