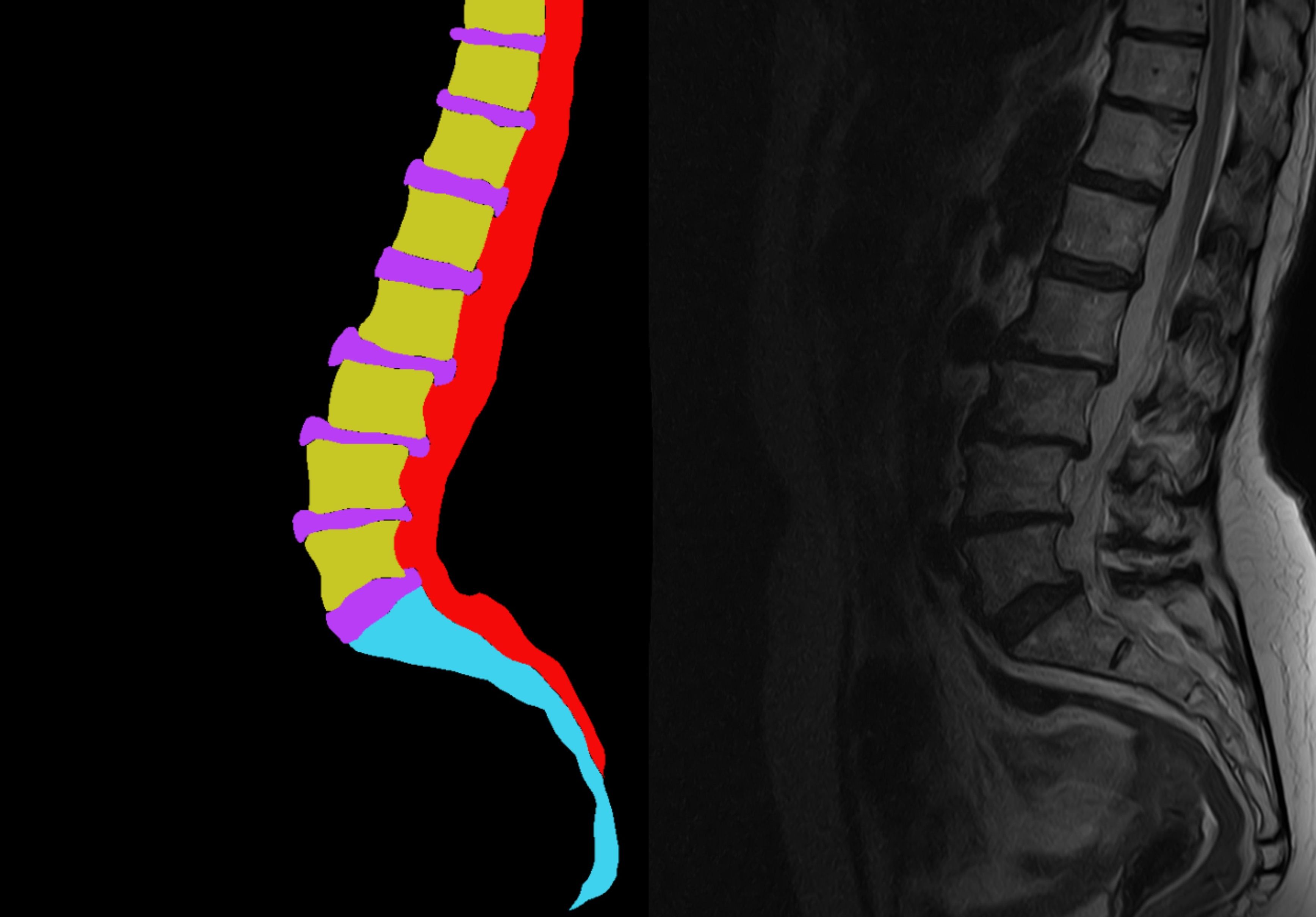
В разработке медицинского ИИ есть классический тупик: чтобы нейросеть научилась находить грыжу позвоночника, ей нужны сотни тысяч примеров, размеченных экспертами. Но если посадить за разметку 500 000 снимков практикующих врачей-рентгенологов, проект станет финансово-неподъемным еще до этапа написания кода, а сроки реализации растянутся на десятилетия.
В этом кейсе мы расскажем, как NeuroCore удалось создать гигантский датасет для международного MedTech-стартапа, используя принцип конвейерного производства, и почему в вопросах качества данных важна не только квалификация, но и методология.
Сбор данных: как получить объём без потери качества
Первая проблема, с которой мы столкнулись: данных в нужном объеме не было. Клиент пришел с запросом на 500 000+ снимков (аксиальные и сагиттальные срезы).
Использование открытых медицинских датасетов и коммерческих архивов не подходило: они либо не обеспечивали нужного объёма и однородности данных, либо имели ограничения по лицензированию и качеству.
Мы пошли нестандартным путем. Единственным устойчивым источником валидных МРТ-снимков оказались практикующие врачи, имеющие доступ к клиническим архивам и понимающие требования к качеству медицинских данных. Это определило дальнейшую стратегию поиска — не датасетов, а профессионального сообщества.
Сначала пробовали классические рекламные объявления и поиск по профильным сообществам рентгенологов. Часть врачей нашли благодаря «сарафанному радио». Мы вышли на врачей из Казахстана, которые согласились помочь с формированием базы.
Важный нюанс: все данные собирались строго анонимно и в обезличенном виде. Мы не просто «покупали снимки», мы выстраивали сеть поставщиков, которые понимали ценность чистого медицинского датасета. Этот «партизанский» маркетинг в профессиональной среде позволил нам собрать базу, которую невозможно найти в официальных репозиториях.
Почему мы отказались от идеи «только врачи-разметчики»
Когда данные были на руках, встал вопрос разметки. У нас было 4 ключевых класса: межпозвоночные диски, жировая ткань, позвоночный канал и Y-образная кость.
Первая мысль любого заказчика: «Нам нужны только врачи».
Мы в NeuroCore смотрим на это иначе. Врач должен лечить и верифицировать, а монотонную многомесячную работу по сегментации лучше выполнит специально обученная команда разметчиков под жестким контролем.
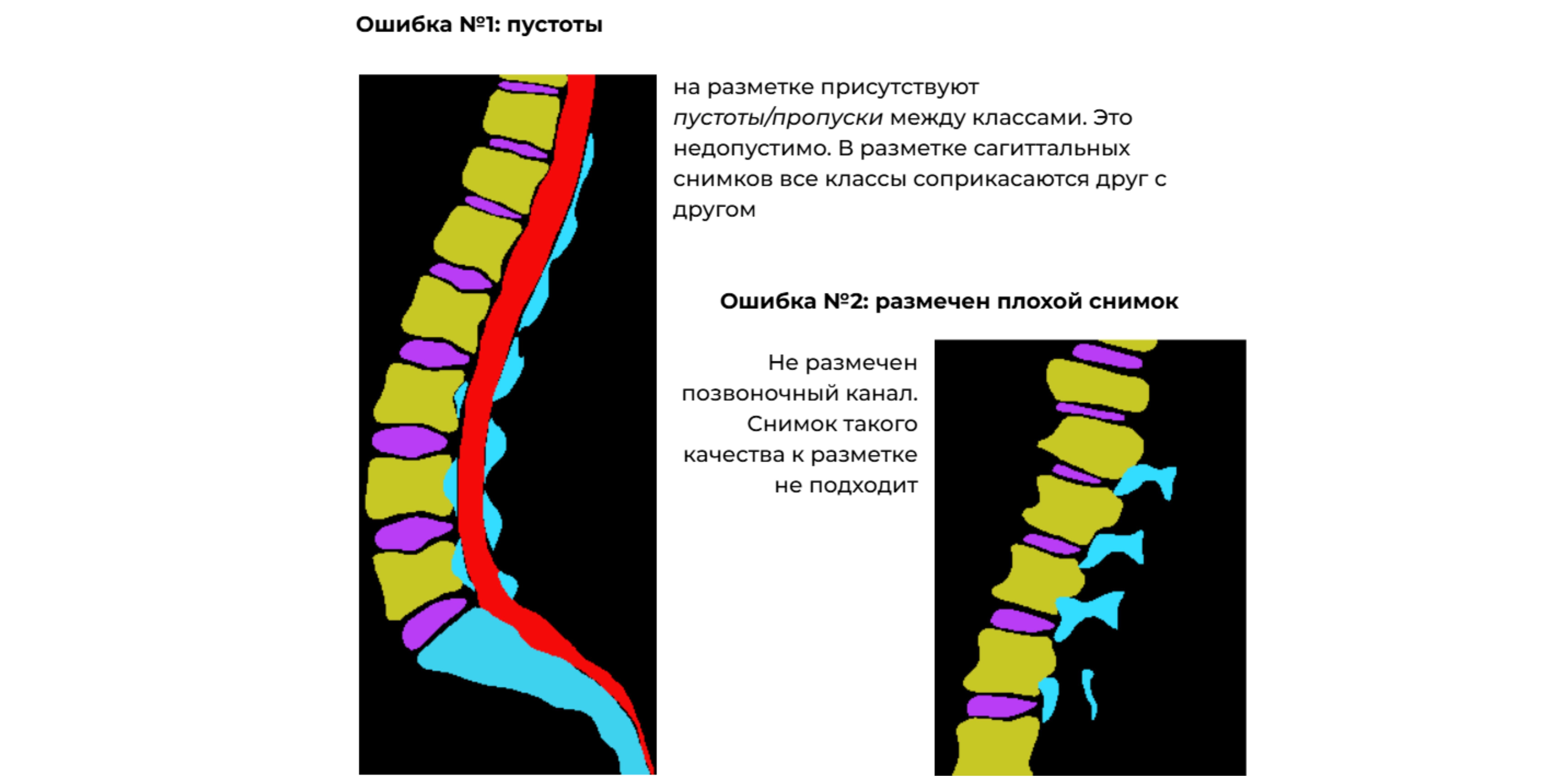
Почему это эффективно:
- Стоимость: экономия бюджета клиента в 3-4 раза.
- Скорость: команда из 25+ обученных людей работает быстрее, чем 2-3 занятых в клиниках врача.
- Фокус: разметчик сфокусирован на точности контура, а врач на проверке разметки.
Секретное оружие: инструкции с гифками
Чтобы обычный человек без медицинского образования начал размечать МРТ с точностью опытного хирурга, нам пришлось создать «Библию проекта».
Мы не просто написали текстовое ТЗ. Вместе с привлеченными рентгенологами мы разработали сверхдетализированные инструкции, где каждый сложный случай (например, вариации отображения жировой ткани на разных снимках МРТ) был проиллюстрирован гиф-анимациями.
Как отличить край диска от тени? — Смотри гифку.
Где заканчивается жировая ткань и начинается позвонок? — Вот пример.
Какой снимок подойдет для разметки? — Показано здесь.
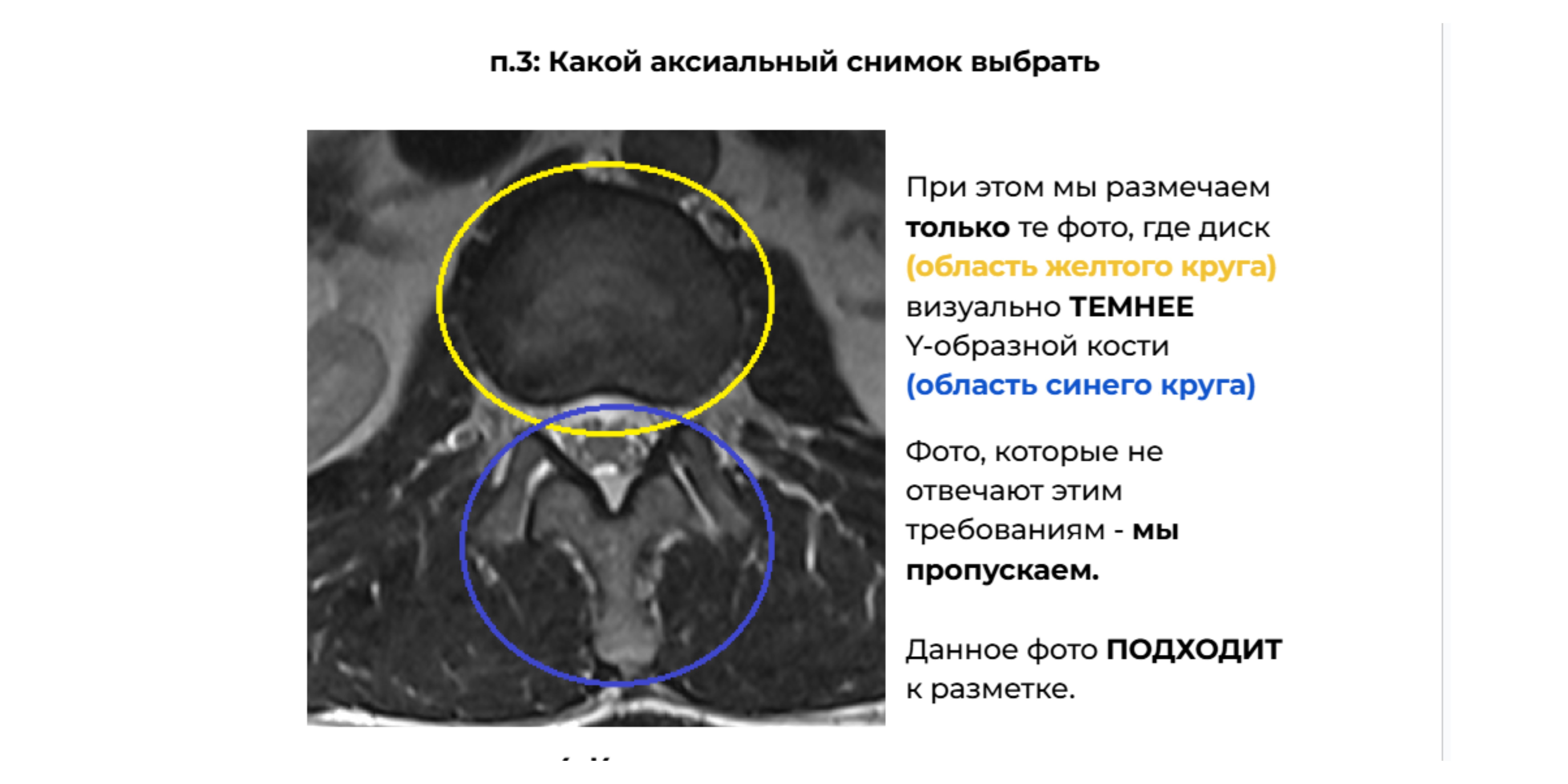
Такой подход позволил нам вывести команду на нужную точность (87,5% по независимому аудиту) всего за пару недель обучения. Люди начали «видеть» патологии так, как их видят профи.
Больше реальных бизнес-кейсов, новостей из мира AI и инсайдов о том, как мы строим процессы, читайте в нашем Telegram-канале NeuroCore. Там мы без купюр рассказываем о внутренней кухне разработки.
Технологический конвейер и контроль качества
Для реализации проекта мы использовали CVAT (для аннотаций) и Python (библиотеки OpenCV, Pydicom) для предобработки файлов DICOM. Но технологии — это лишь инструменты. Главным был процесс валидации:
- Первый уровень: разметка выполняется рядовым разметчиком.
- Второй уровень: проверка старшим разметчиком (куратором).
- Третий уровень (экспертный): врачи-кураторы проверяют только сложные и спорные случаи, а также делают выборочный аудит 10-15% каждого батча.
Если на «консилиуме» врачей возникали разночтения (а медицина — штука субъективная), мы вырабатывали «золотой стандарт» для этого конкретного случая и вносили его в инструкцию.
Результат: экономия года жизни проекта
За 12 месяцев мы разметили и валидировали более полумиллиона снимков.
Что получил клиент:
- Готовый, идеально структурированный датасет для обучения модели.
- Экономию 9–12 месяцев R&D (если бы они собирали команду сами).
- Чистую архитектуру данных, готовую к загрузке в нейросеть без «костылей».
Этот кейс показывает, что при правильной организации процессов сбор и разметка медицинских данных могут быть вынесены в отдельный контур без потери качества. Это позволяет команде заказчика сосредоточиться на обучении моделей и развитии продукта, не тратя ресурсы на операционную работу с данными.
Нужны качественные данные для вашего проекта?
Мы в NeuroCore специализируемся на сборе и разметке сложных датасетов, в том числе для проектов с особой спецификой.
Подготовим для вас индивидуальный план работ и поможем выстроить конвейер разметки, который сэкономит ваше время и бюджет. Тестовый датасет — бесплатно.
Оставить заявку в форме ниже | Читать наши кейсы | Написать нам в ТГ



