В основе любого эффективного ИИ-решения - данные. Много данных. Качественных данных.
Именно они определяют, сможет ли искусственный интеллект решать поставленную бизнес-задачу или окажется бесполезной инвестицией. Однако сами по себе сырые данные — это просто цифровой шум. Чтобы превратить их в топливо для машинного обучения, необходимы два ключевых процесса: сбор и разметка.
Давайте разберемся, в чем разница между этими этапами, когда можно обойтись готовыми решениями, а когда жизненно необходимо создавать собственный уникальный датасет, и как мы, как компания-разработчик, подходим к этому процессу.

Сбор и разметка данных: две стороны одной медали
Часто эти понятия смешивают, но крайне важно их различать.
Сбор данных (Data Collection) — это первый и фундаментальный этап.
Его цель — получить исходный, «сырой» материал. Это могут быть часы видео с промышленных камер, фотографии продукции, тексты отзывов, медицинские снимки, аудиозаписи звонков. На этом этапе мы фокусируемся на количестве и разнообразии материала, покрывающего все возможные условия и сценарии. Без сбора данных размечать попросту нечего.
Разметка данных (Data Annotation) — это второй, интеллектуальный этап. Здесь мы берем сырой материал и обогащаем его, превращая в структурированную информацию, понятную для машины. В соответствии с бизнес-задачей мы выделяем и подписываем на данных нужные объекты (классы).
Простая аналогия: представьте, что вы учите ребенка распознавать фрукты.
Сбор данных — это поход в магазин, где вы покупаете яблоки, бананы, апельсины, груши — разные по цвету, размеру и форме.
Разметка данных — это когда вы показываете ребенку каждый фрукт и говорите: «Это — яблоко. Это — банан. А вот это — тоже яблоко, но зеленое».
Без похода в магазин (сбора) вам нечего будет показывать. А без ваших объяснений (разметки) для ребенка это будет просто набор непонятных предметов.
Зачем вообще собирать данные? Неужели нет готовых?
Основной фокус нашей работы — создание кастомных ИИ-решений, и именно поэтому для нас сбор данных — критически важный процесс. Готовые (публичные или покупные) датасеты хороши для общих задач, но когда речь идет о решении уникальной бизнес-проблемы, они почти всегда оказываются неэффективны.
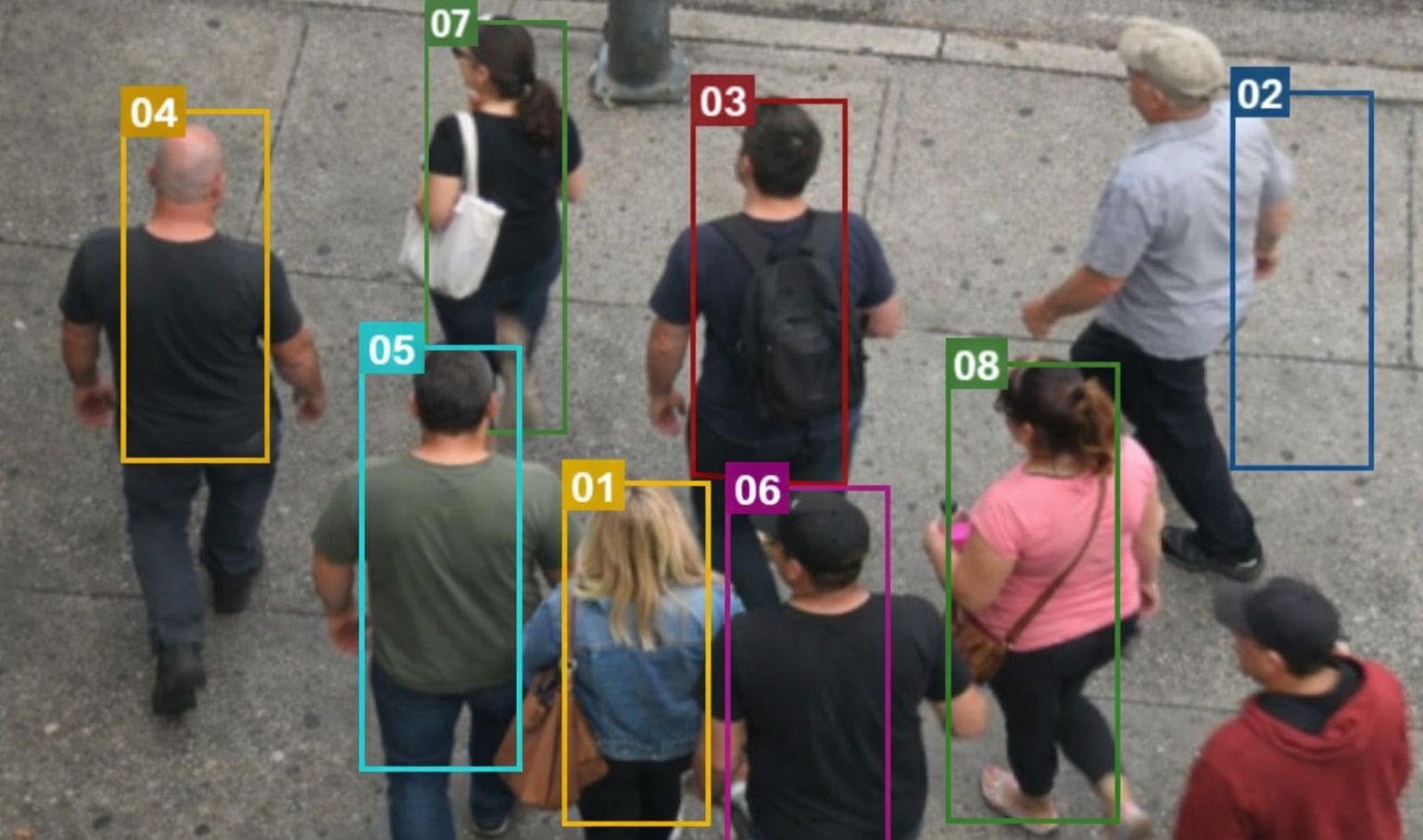
Когда можно обойтись без собственного сбора?
- Покупка готового датасета. Это оправдано для стандартных, давно решенных задач: распознавание лиц, классификация обычных объектов (люди, машины, животные), определение эмоций. Если ваша задача укладывается в эти рамки, покупка данных может ускорить запуск проекта. Но будьте готовы, что точность на ваших специфических данных (например, распознавание сотрудников в касках и спецодежде в полутемном цеху) будет ниже заявленной.
- Использование синтетических данных. Синтетика — это данные, сгенерированные компьютером, а не снятые в реальном мире. Это мощный инструмент, но не панацея. Его используют:
- Для аугментации: когда реальных данных мало, их можно "размножить", добавив синтетические вариации.
- Для редких или опасных сценариев: проще сгенерировать 1000 изображений аварии на производстве, чем ждать, пока они произойдут в реальности.
- Для сложных условий: Создание моделей для работы в тумане, дыму или под водой, где реальная съемка затруднена.
Важно понимать, что синтетика хороша как дополнение к реальным данным, а не их полная замена, чтобы избежать "разрыва домена" (domain gap) — ситуации, когда модель отлично работает на симуляциях, но проваливается в реальной жизни. Подробнее об этом мы писали в нашей статье о синтетических данных.
Когда собственный датасет — это необходимость?
Ответ прост: практически всегда, когда вы решаете уникальную для вашего бизнеса задачу. Если бы решение было стандартным, оно бы уже существовало в виде коробочного продукта.
Вот несколько направлений, где без кастомного датасета не обойтись:
Промышленность и производство:
- Задача: контроль качества уникальной продукции (например, поиск микротрещин на лопатках турбин, дефектов сварных швов).
- Почему нужен свой датасет: ни один публичный датасет не содержит изображений именно вашей продукции со всеми специфическими видами брака. Модель нужно обучить на сотнях и тысячах примеров как качественных, так и дефектных изделий именно с вашей производственной линии.

Ритейл:
- Задача: анализ поведения покупателей, контроль выкладки товаров на полках, предотвращение краж.
- Почему нужен свой датасет: расположение полок, освещение, ассортимент и даже поведение покупателей в вашем магазине уникальны. Модель, обученная на данных из американского супермаркета, будет неэффективна в российском дискаунтере.
Сельское хозяйство:
- Задача: определение болезней растений, подсчет урожая, обнаружение сорняков.
- Почему нужен свой датасет: внешний вид пшеницы в Краснодарском крае отличается от пшеницы в Сибири. Типы сорняков, болезни, стадии созревания — все это требует сбора локальных данных.
Безопасность:
- Задача: контроль ношения СИЗ (средств индивидуальной защиты), мониторинг опасных зон, обнаружение запрещенных предметов.
- Почему нужен свой датасет: спецодежда на вашем предприятии имеет уникальный вид. Опасные зоны и оборудование также специфичны. Модель нужно обучить отличать вашего сотрудника в каске от гостя и понимать, что приближение к этому конкретному станку на 2 метра — это нарушение.
Как мы собираем данные: наш подход и стек
Сбор данных для нас — это полноценный R&D-проект, который включает несколько этапов.
Что входит в задачи по сбору данных?
- Аудит и ТЗ: мы начинаем с глубокого погружения в задачу клиента. Что и с какой точностью нужно детектировать? В каких условиях? От этого зависит вся дальнейшая стратегия.
- Проектирование системы сбора: Мы определяем, какие инструменты нужны, например, если речь про камеры, то решаем под каким углом их ставить, какое необходимо разрешение и светочувствительность.
- Инженерная или организационная подготовка: Зачастую это самая сложная часть.
Кейс (вибрация при сборе датасета): для задачи по предиктивному анализу износа конвейерной ленты пришлось разработать специальную виброгасящую конструкцию, так как из-за вибрации станка изображение было смазанным.
Кейс (регулирование температуры при сборе датасета): в том же проекте камера была помещена в промышленный термокожух с охлаждением, чтобы защитить ее от высоких температур цеха.
Кейс (заказ датасета со сценами агрессивного поведения, драками): для клиента, который разрабатывал ИИ для предотвращения драк мы снимали датасет, где требовалось имитировать рукоприкладство. Для этих целей мы нашли и наняли актеров из бойцовского клуба.
- Сбор сырых данных: команда NeuroCore выезжает на объект или настраивает удаленный сбор. Мы следим, чтобы были охвачены все условия: разное время суток, погодные условия, разная степень загруженности цеха.
- Валидация данных: первичный отсев брака: засвеченные кадры, не в фокусе, без целевых объектов.
Разметка данных — превращение сырых данных в готовый к использованию датасет
Если сбор данных — это добыча "нефти", то разметка — это ее переработка в "топливо" для нейросетей. Без этого этапа сырые данные бесполезны для обучения большинства моделей.
Что такое разметка данных?
Это процесс добавления метаданных (меток, аннотаций) к сырым данным, который объясняет модели, на что именно ей нужно обращать внимание.
Основные виды разметки (на примере компьютерного зрения):
- Классификация (Classification): самый простой вид. Каждому изображению присваивается одна метка (например, "кошка", "собака").
- Детекция (Object Detection): на изображении с помощью прямоугольных рамок (bounding boxes) выделяются интересующие объекты и им присваиваются классы.
- Сегментация (Segmentation):
- Семантическая сегментация: каждый пиксель изображения классифицируется (например, все пиксели, относящиеся к "дороге", окрашиваются в один цвет, к "небу" — в другой).
- Инстанс сегментация (Instance Segmentation): более сложный вид, который не только классифицирует пиксели, но и выделяет отдельные экземпляры объектов (например, отличает "человека 1" от "человека 2"). - Оценка поз и ключевые точки (Keypoint Estimation): разметка ключевых точек на объектах (например, суставы на теле человека для анализа движений или точки на лице для распознавания эмоций).
Процесс качественной разметки:
- Разработка инструкции - важный шаг. Создается детальный документ с правилами и примерами разметки, который исключает любую двусмысленность. Что считать "пешеходом"? Включать ли в рамку тень от объекта? Все это должно быть строго регламентировано.
- Выбор инструментов: подбирается платформа для разметки (CVAT, LabelStudio, LabelMe или собственный кастомный инструмент разметки), которая наиболее удобна для конкретного типа задач.
- Обучение и калибровка разметчиков: кеоманда разметчиков проходит обучение по инструкции и выполняет тестовые задания. Их результаты сравниваются с эталонной разметкой для оценки качества.
- Итеративная разметка и контроль качества: разметка выполняется итерациями. После каждой итерации проводится выборочный или полный аудит качества. Задания с ошибками возвращаются на доработку.
- Применение моделей-помощников: для ускорения процесса используются предобученные модели, которые делают предварительную разметку, а человек-разметчик только проверяет и исправляет ее. Это значительно повышает производительность.
Собственный, готовый или синтетический датасет?
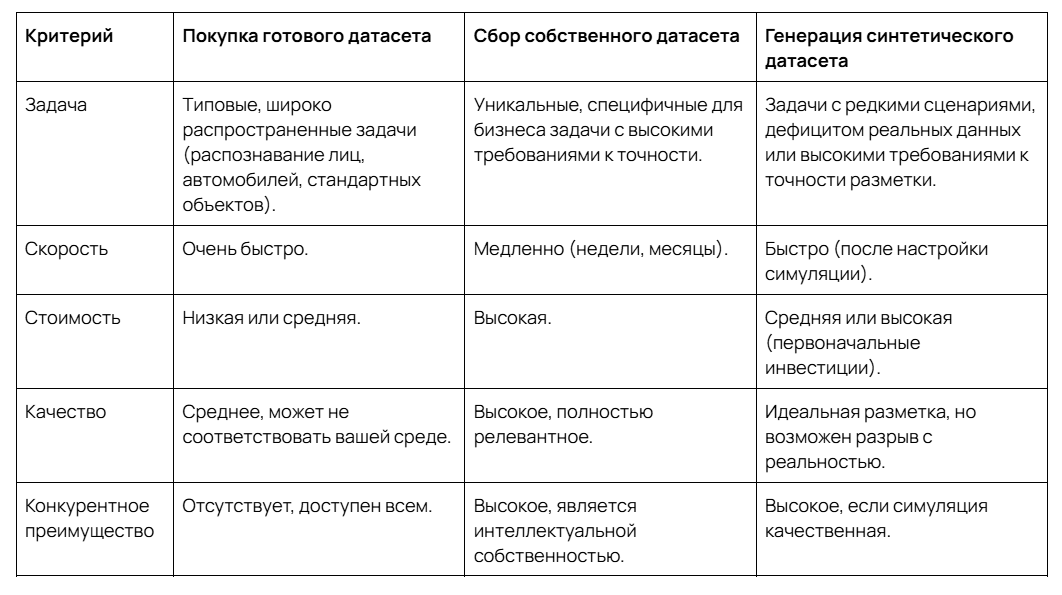
Для многих проектов используется гибридный подход. Это когда за основу берется небольшой, но очень качественный собственный датасет, который затем расширяется (аугментируется) с помощью парсинга и синтетической генерации для покрытия всех возможных сценариев.
Выводы
Данные — это фундамент. Качество вашего ИИ-решения на 90% зависит от качества собранного и размеченного датасета.
Нет универсальных решений. В 9 из 10 случаев для решения реальной бизнес-задачи требуется создание кастомного набора данных, учитывающего всю специфику вашего окружения и процессов.
Сбор данных — это инжиниринг. Это не просто «нажать на запись». Это сложный процесс, требующий экспертизы в самом сборе, иногда в оптике, электронике, программировании и глубокого понимания предметной области клиента.
Инвестиции в разработку качественного датасета — это не затраты, а вложения в долгосрочное конкурентное преимущество. В современной экономике данных компания, обладающая уникальным и чистым датасетом, имеет гораздо больше шансов на успех, чем компания с самой продвинутой моделью, но обученной на "грязных" данных из открытых источников.
Хотите гарантированно получить качественный датасет?
Напишите нам и доверьте сбор для вашего ИИ специалистам, выполнившим сотни проектов по подготовке датасетов для крупных клиентов из разных сфер: промышленность, автопилоты, медицина, безопасность и другие.
Как работаем:
Сначала тест — потом КП. Бесплатно делаем пробную разметку/сбор, чтобы вы оценили качество, а мы точнее рассчитали сроки и бюджет.
Какие задачи берем:
- Сбор данных (парсинг, съемки, обработка);
- Классическая разметка (текст, изображения, видео, таблицы);
- Сложная разметка (где нужны эксперты или особые навыки).
- Закроем почти любой запрос — просто расскажите о нем:
Оставить заявку в форме ниже | Читать наши кейсы | Написать нам в ТГ
А ещё у нас есть интересный Telegram-канал. Приглашаем подписаться: там регулярно появляются наши кейсы и полезные материалы!